
深度学习笔记
[TOC]
神经网络和深度学习(Neural Networks and Deep Learning)
神经网络
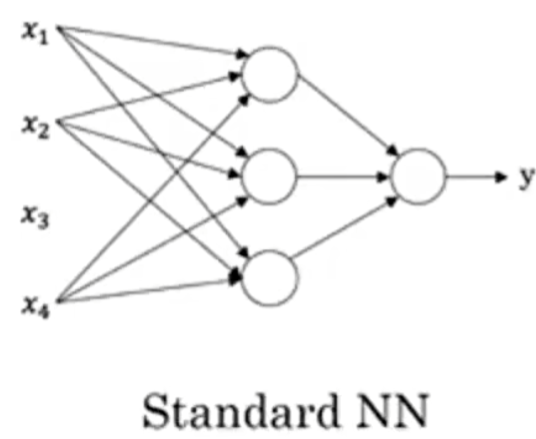
这就是一个简单的神经网络,其中的每一个箭头就代表一个ReLU函数
监督学习
数据
结构化数据:表格
非结构化数据:文本、图像、音频
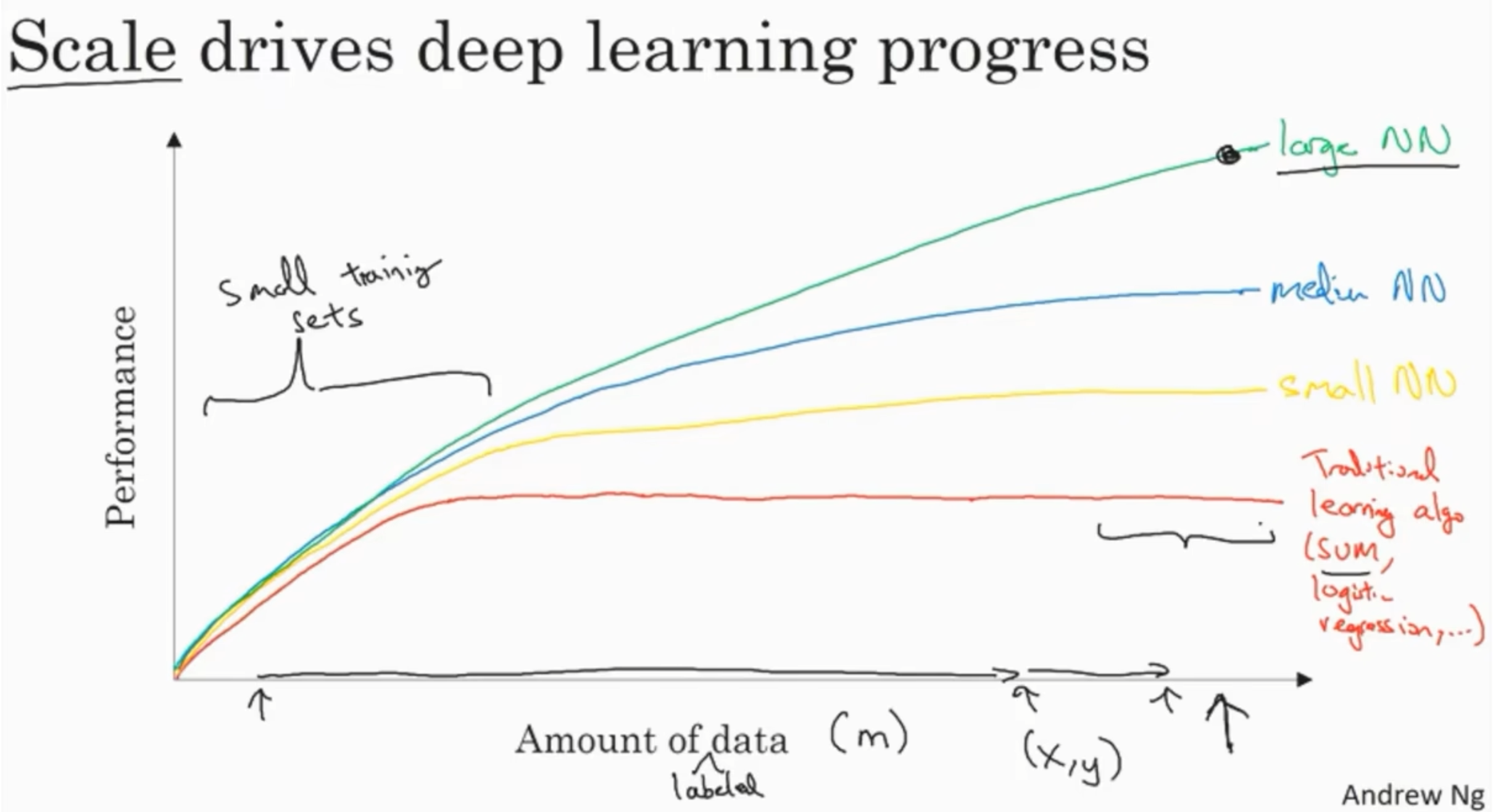
深度学习兴起
神经网络越大、数据集越大,神经网络性能越好。
数据集不够大的时候,自己提取出来的特征和算法实现细节决定了算法的性能和表现。
神经网络的编程基础(Basics of Neural Network programming)
二分分类
一些符号
一个单独的样本:
训练集将由
有时候为了强调这是训练样本的个数,会写作
Logistic回归
给定信息
- 给定:
,我们希望
参数
, 拦截器,把b和w视为独立的参数会更好
输出
Sigmoid函数
- Sigmoid函数
定义为: - 当
很大时, - 当
为大负数时,
Sigmoid函数的图像
- Sigmoid函数具有S形曲线,将任何输入映射到0和1之间的值。
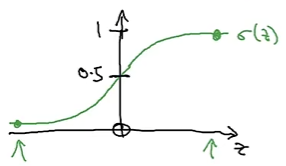
- 当
很大时, - 当
为大负数时,
- 当
重要说明
- 对于大的
, - 对于大的负数
,
逻辑回归的代价函数(Logistic Regression Cost Function)
需要一个代价函数,通过训练代价函数来得到参数
逻辑回归成本函数
- 预测值:
- 给定数据集
,我们希望:
损失(误差)函数(单个样本)
Logistic回归的损失函数:
称为损失函数,来衡量预测输出值和实际值有多接近。一般我们用预测值和实际值的平方差或者它们平方差的一半,但是通常在逻辑回归中我们不这么做,因为当我们在学习逻辑回归参数的时候,会发现我们的优化目标不是凸优化,只能找到多个局部最优值,梯度下降法很可能找不到全局最优值. - 在逻辑回归中用到的损失函数是对数损失(交叉熵):
- 在逻辑回归中用到的损失函数是对数损失(交叉熵):
当
时: 当
时: 在这门课中有很多的函数效果和现在这个类似,就是如果
等于1,我们就尽可能让 变大,如果 等于0,我们就尽可能让 变小。
成本函数(所有样本)
- 成本函数是所有样本的损失平均值:
Logistic回归可以被看做是一个非常小的神经网络
梯度下降法
假设函数为:
成本函数为:
其中,逻辑损失函数定义为:
目标:
我们希望找到能够最小化成本函数
图示:
优化目标是最小化
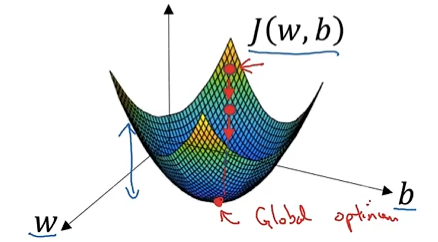
轴 轴 轴,红点为全局最小值。
因为函数是凸函数,无论在哪里初始化,应该达到同一点或大致相同的点。如果每次都选定从0开始不断下降直至找到全局最优解,则就叫梯度下降
梯度下降过程
在梯度下降过程中,随着每一步的更新,权重
其中
同样,对于偏置
图示:
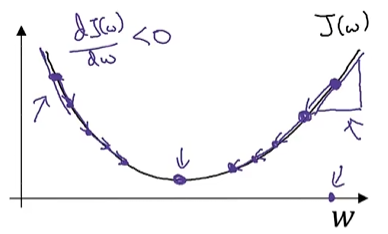
在图示中,展示了梯度下降的路径,沿着曲线的方向进行更新,每次迭代向着函数值更小的方向移动,直到达到最小值。
- 箭头指向梯度下降的方向。
- 目标是通过不断更新
和 ,使得损失函数 最小化。
在程序中dvar变量表示对最终值的导数
Logistic Regression 中的梯度下降(Logistic Regression Gradient Descent)
前向传播
输入特征
Sigmoid激活函数:
损失函数(二元交叉熵,单个样本):
代价函数:
计算图表示
x₁ x₂
| |
w₁ w₂
\ /
[z = w₁x₁ + w₂x₂ + b]
|
a = σ(z)
|
L(a,y)
反向传播导数
关键梯度计算
损失对输出的导数:
Sigmoid函数的导数:
链式法则求
:
参数梯度
计算
- 权重梯度:
- 偏置梯度:
关于单个样本的梯度下降算法,所需要做的就是如下的事情:
- 使用公式
计算 , - 使用
计算 , 计算 , 来计算 , - 然后:
- 更新
, - 更新
, - 更新
。
这就是关于单个样本实例的梯度下降算法中参数更新一次的步骤。
参数更新规则
梯度下降更新(学习率
实例演示
示例数据
假设输入样本和参数:
逐步计算
前向传播:
损失计算:
反向传播:
参数更新(学习率
):
关键理解
导数简化:最终梯度形式
是Logistic回归的优美性质 向量化实现:实际代码中应使用:
1
2dw = np.dot(X, (A-Y).T)/m
db = np.sum(A-Y)/m
Logistic Regression on
1. 成本函数(Cost Function)
逻辑回归的目标是最小化所有训练样本上的损失函数平均值,其成本函数定义为:
其中:
是 sigmoid 激活函数 是逻辑回归的交叉熵损失:
2. 目标函数的梯度计算
为了使用梯度下降法更新参数
2.1 对
将损失函数代入并链式求导,得到:
因此:
2.2 对
3. 梯度下降算法实现(带循环)
初始化参数:
1 | J = 0 |
对于每个样本
3.1 前向传播
3.2 损失和梯度计算
误差项:
累加梯度:
3.3 最终平均值
4. 参数更新(梯度下降)
给定学习率
代码流程
1 | J=0;dw1=0;dw2=0;db=0; |
应用此方法在逻辑回归上你需要编写两个for循环。第一个for循环是一个小循环遍历
向量化(Vectorization)
基本概念
向量化是指将显式循环操作转换为矩阵/向量运算的过程,利用线性代数库(如NumPy)或硬件加速(如GPU)来提升计算效率。核心思想是用单条指令处理多条数据(SIMD)。
数学表达
非向量化实现
给定参数和输入 ,偏置 ,标量输出 的计算为:
若和 为二维向量: 循环示例
以下伪代码展示了非向量化的逐元素计算(效率低):1
2
3
4z = 0
for i in range(log2(n - x)):
z += ω[i] * x[i] # 逐元素相乘累加
z += b
向量化实现
直接矩阵运算
使用库函数(如NumPy)将上述操作简化为:
其中等价于 。 硬件加速
向量化计算可映射到GPU的SIMD(单指令多数据)架构:
实例说明
场景:计算批量数据的线性变换。
- 非向量化:需遍历每个样本和特征。
- 向量化:将数据堆叠为矩阵
( 为样本数),一次性计算:
其中为所有样本的输出向量。
优势总结
- 性能提升:减少显式循环,利用优化库和硬件并行能力。
- 代码简洁:数学表达式更贴近理论推导(如
)。 - 扩展性:易于扩展到批量数据处理(如深度学习中的全连接层)。
向量与矩阵值函数的逐元素运算
基本概念
当需要对矩阵或向量的每个元素应用指数函数等逐元素运算时,数学表示为:
给定向量
Python实现示例
手动循环实现
1 | import numpy as np |
使用NumPy内置函数
NumPy提供了高效的逐元素运算函数:
1 | u = np.exp(v) # 指数运算 |
逐元素运算的数学性质
- 线性与非线性的区别:
例如,是线性运算,而 是非线性运算。 - 广播机制:
类似的运算会触发NumPy的广播规则,要求维度匹配或可广播。
应用场景
- 激活函数:如ReLU (
) 和Sigmoid(可通过指数实现)。 - 梯度计算:在反向传播中需处理逐元素导数的链式法则
在能够使用Numpy内置函数的时候尽量使用内置函数
向量化的示例应用
广播机制(Broadcasting)
原理
当操作不同维度的数组时,NumPy会自动扩展较小数组的维度以匹配大数组(无需显式复制数据)。例如:实例
计算批量数据时,偏置会自动广播到每个样本: 1
2
3
4
5import numpy as np
W = np.array([1, 2]) # shape (2,)
X = np.array([[1, 2], [3, 4]]) # shape (2,2)
b = 10
Z = np.dot(X, W) + b # b被广播为 [10, 10]
向量化的梯度计算
理论推导
对于损失函数,其梯度计算也可向量化。设样本矩阵 ,标签 : 代码实现
1
2dW = np.dot(X.T, (Z - y)) / m # 向量化梯度
db = np.sum(Z - y) / m # 标量广播
避免常见错误
维度匹配
需确保矩阵乘法维度对齐。例如:要求 和 同维度。 要求 的列数等于 的行数。
显式reshape
当输入维度不明确时,需手动调整:1
x = x.reshape(-1, 1) # 确保列向量
实际案例:逻辑回归
假设函数
向量化实现Sigmoid激活:损失函数
完整代码片段
1
2
3
4
5
6def sigmoid(z):
return 1 / (1 + np.exp(-z))
Z = np.dot(W.T, X) + b
A = sigmoid(Z)
cost = -np.mean(Y * np.log(A) + (1 - Y) * np.log(1 - A))
性能对比
| 方法 | 时间(m=10,000) | 代码复杂度 |
|---|---|---|
| 非向量化循环 | 2.3s | 高 |
| 向量化 | 0.002s | 低 |
注:向量化在数据量大时优势更显著,加速可达1000倍以上。
向量化逻辑回归的实现

单样本计算基础
对于单个样本
- 线性变换:
- 激活函数(Sigmoid):
向量化批量计算
输入数据矩阵
将
并行计算所有
线性部分:
Python实现:1
Z = np.dot(w.T, X) + b # 向量化实现
激活部分:
矩阵维度说明
的维度: 广播机制:标量
会自动加到 的每个元素上。 是样本矩阵,每列一个样本。 是行向量,包含所有样本的线性输出。
优势
- 效率提升:避免显式循环,利用NumPy的并行计算加速。
- 代码简洁性:一行代码完成全部样本的计算。
向量化 logistic 回归的梯度输出(Vectorizing Logistic Regression’s Gradient)
本节中大写字母代表向量,小写字母代表元素
对

我们已经去掉了一个for循环,我们的目标是不使用for循环,而是向量,我们可以这么做:
${dw = \frac{1}{m}Xdz^{T}\ }$
现在我们利用前五个公式完成了前向和后向传播,也实现了对所有训练样本进行预测和求导,再利用后两个公式,梯度下降更新参数,所以我们就通过一次迭代实现一次梯度下降,但如果希望多次迭代进行梯度下降,那么仍然需要for循环,放在最外层。
Python 中的广播(Broadcasting in Python)
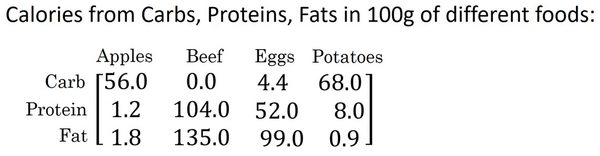
这是一个不同食物(每100g)中不同营养成分的卡路里含量表格,表格为3行4列,列表示不同的食物种类,从左至右依次为苹果,牛肉,鸡蛋,土豆。行表示不同的营养成分,从上到下依次为碳水化合物,蛋白质,脂肪。
那么,我们现在想要计算不同食物中不同营养成分中的卡路里百分比。
1 | import numpy as np |
输出:
1 | [[ 56. 0. 4.4 68. ] |
按列求和(计算每列总和)
1 | cal = A.sum(axis=0) # axis=0表示沿列方向求和 |
输出:
1 | [ 59. 239. 155.4 76.9] |
计算百分比(归一化每列)
1 | percentage = 100 * A / cal.reshape(1, 4) # reshape确保广播正确 |
输出:
1 | [[94.91525424 0. 2.83140283 88.42652796] |
关键说明
A.sum(axis = 0)中的参数axis。axis用来指明将要进行的运算是沿着哪个轴执行,在numpy中,0轴是垂直的,也就是列,而1轴是水平的,也就是行。- 而第二个
A/cal.reshape(1,4)指令则调用了numpy中的广播机制。这里使用的矩阵 除以 的矩阵 。技术上来讲,其实并不需要再将矩阵 reshape(重塑)成,因为矩阵 本身已经是 了。但是当我们写代码时不确定矩阵维度的时候,通常会对矩阵进行重塑来确保得到我们想要的列向量或行向量。重塑操作 reshape是一个常量时间的操作,时间复杂度是,它的调用代价极低。
广播的例子
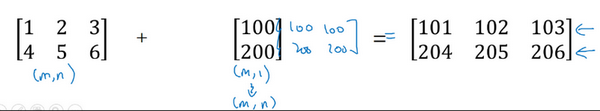
这里相当于是一个
广播机制原则
numpy广播机制
如果两个数组的后缘维度的轴长度相符或其中一方的轴长度为1,则认为它们是广播兼容的。广播会在缺失维度和轴长度为1的维度上进行。
后缘维度的轴长度:A.shape[-1] 即矩阵维度元组中的最后一个位置的值
对于视频中卡路里计算的例子,矩阵 axis=0,即垂直方向,矩阵 $${cal}{1,4}$$ 沿axis=0(垂直方向)复制成为 ${cal{temp}}_{3,4}$ ,之后两者进行逐元素除法运算。

矩阵
矩阵
矩阵 axis=0,轴长度为1的轴是axis=1,即
关于 python _ numpy 向量的说明(A note on python or numpy vectors)
一维数组的陷阱
1 | import numpy as np |
1 | print(a.T) |
编写神经网络时,不要使用shape为 (5,)、(n,) 或者其他一维数组的数据结构。相反,如果你设置
所以,不要使用
还有一件经常做的事,那就是如果我不完全确定一个向量的维度(dimension),我经常会扔进一个断言语句(assertion statement)。像这样:
1 | a = np.random.randn(5, 1) |
去确保在这种情况下是一个
1 | assert(a.shape == (5,1)) |
不要使用一维数组,总是使用
一维数组的陷阱与最佳实践(这里是ai总结的本节笔记,用于对比看看哪个更清晰,使用Qwen2.5-Max)
在使用 NumPy 编写神经网络或进行矩阵运算时,正确处理数组的维度是非常重要的。如果不小心使用了一维数组(shape 为 (n,)),可能会导致一些不易察觉的错误和计算问题。以下是对常见陷阱的总结以及如何避免它们的最佳实践。
一维数组的问题
形状模糊
使用a = np.random.randn(5)创建的一维数组,其 shape 为(5,),既不是行向量也不是列向量。这种数组的行为在某些操作中可能会让人困惑。例如:1
2
3a = np.random.randn(5)
print(a.shape) # Output: (5,)
print(a.T) # Output: [ ... ] (转置后仍然是相同的一维数组)点积结果不符合预期
如果你对两个一维数组进行点积(np.dot(a, a.T)),结果会是一个标量值(内积)。这可能不是你想要的结果,尤其是当你期望一个矩阵乘法时:1
print(np.dot(a, a.T)) # Output: 标量值(如 4.0657109321)
缺乏明确的方向性
一维数组没有明确的“方向”(行或列),这可能导致后续操作中的维度不匹配问题。例如,矩阵乘法需要明确的行向量或列向量。
推荐的最佳实践
为了避免上述问题,建议始终使用明确的二维数组,即列向量(n × 1)或行向量(1 × n)。以下是具体方法和注意事项:
1. 明确使用二维数组
创建数组时,确保它的 shape 是 (n, 1) 或 (1, n),而不是 (n,)。例如:
1 | # 列向量 (n × 1) |
这样可以确保数组具有明确的方向性,并且在矩阵运算中行为可预测。
2. 使用断言语句验证维度
为了确保数组的维度符合预期,可以在代码中插入断言语句。例如:
1 | # 确保 a 是一个列向量 |
这些断言语句可以帮助你在开发过程中快速发现维度错误。
3. 使用 reshape 调整维度
如果你已经有一个一维数组,可以通过 reshape 方法将其转换为列向量或行向量。例如:
1 | # 从一维数组转换为列向量 |
reshape 是一种非常灵活的方法,可以确保你的数据结构符合预期。
4. 注意转置操作
对于二维数组,转置操作会交换行和列。例如:
1 | # 列向量的转置 |
注意转置后的形状变化,并确保它符合你的计算需求。
5. 避免混用一维数组和二维数组
在编写代码时,尽量避免混用一维数组和二维数组。如果你必须处理一维数组,尽早将其转换为二维数组。例如:
1 | # 假设你有一维数组 |
总结
- 不要使用一维数组 (
(n,)),始终使用明确的二维数组(列向量(n, 1)或行向量(1, n))。 - 使用断言语句 验证数组的维度,确保它们符合预期。
- 使用
reshape或[:, None]将一维数组转换为二维数组。 - 注意转置操作 的影响,确保矩阵运算的行为符合预期。
通过遵循这些最佳实践,你可以避免许多潜在的维度错误,并使代码更加清晰和健壮。
最终建议:始终以二维数组的形式处理数据,明确方向性和维度,减少调试时间并提高代码可靠性。
Boxed Final Recommendation:
3 浅层神经网络(Shallow neural networks)
3.1 神经网络概述(Neural Network Overview)
首先你需要输入特征
接下来使用

在这个神经网络对应的3个节点,首先计算第一层网络中的各个节点相关的数
我们会使用符号
整个计算过程如下:
类似逻辑回归,在计算后需要使用计算,接下来你需要使用另外一个线性方程对应的参数计算
计算
在神经网络中我们也有从后向前的计算,最后会计算
3.2 神经网络的表示(Neural Network Representation)

记号
这是一个两层的神经网络,因为我们计算网络的层数时,输入层是不算入总层数内,所以隐藏层是第一层,输出层是第二层。
隐藏层以及最后的输出层是带有参数的,这里的隐藏层将拥有两个参数

3.3 计算一个神经网络的输出(Computing a Neural Network’s output)
3.3.1 神经网络的计算

首先按步骤计算出
针对上面的两层的神经网络:
第一步,计算
第二步,通过激活函数计算
隐藏层的第二个以及后面两个神经元的计算过程一样,只是注意符号表示不同,最终分别得到
3.3.2 向量化计算

向量化的过程是将神经网络中的一层神经元参数纵向堆积起来,例如隐藏层中的
因此,
公式3.8:
公式3.9:
详细过程见下:
公式3.10:
$$
a^{[1]} =
\left[
\begin{array}{c}
a^{[1]}{1}\
a^{[1]}{2}\
a^{[1]}{3}\
a^{[1]}{4}
\end{array}
\right]
= \sigma(z^{[1]})
\left[
\begin{array}{c}
z^{[1]}{1}\
z^{[1]}{2}\
z^{[1]}{3}\
z^{[1]}{4}\
\end{array}
\right]
=
\overbrace{
\left[
\begin{array}{c}
…W^{[1]T}{1}…\
…W^{[1]T}{2}…\
…W^{[1]T}{3}…\
…W^{[1]T}{4}…
\end{array}
\right]
}^{W^{[1]}}
*
\overbrace{
\left[
\right]
}^{input}
+
\overbrace{
\left[
\right]
}^{b^{[1]}}
$$
对于神经网络的第一层,给予一个输入
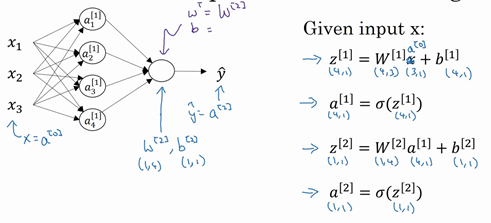
如上图左半部分所示为神经网络,把网络左边部分盖住先忽略,那么最后的输出单元就相当于一个逻辑回归的计算单元。当你有一个包含一层隐藏层的神经网络,你需要去实现以计算得到输出的是右边的四个等式,并且可以看成是一个向量化的计算过程,计算出隐藏层的四个逻辑回归单元和整个隐藏层的输出结果,如果编程实现需要的也只是这四行代码。
3.4 多样本向量化(Vectorizing across multiple examples)
3.4.1 多样本的神经网络计算
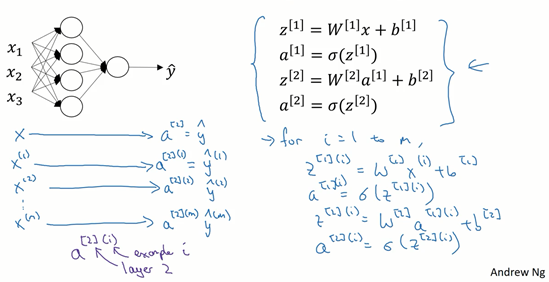
逻辑回归是将各个训练样本组合成矩阵,对矩阵的各列进行计算。神经网络是通过对逻辑回归中的等式简单的变形,让神经网络计算出输出值。这种计算是所有的训练样本同时进行的。
用第一个训练样本
然后,用
用激活函数表示法,如上图左下所示,它写成$a^{2}
$a^{2}
3.4.2 向量化多样本神经网络计算

如果采用非向量化的实现,我们就需要使用for循环遍历每一个训练样本(左上角),所以接下来我们要让这个过程向量化。
定义向量
同理,$z^{1}
Z^{[1]} =
\left[
\begin{array}{c}
\vdots & \vdots & \vdots & \vdots\
z^{1} & z^{1} & \cdots & z^{1}\
\vdots & \vdots & \vdots & \vdots\
\end{array}
\right]
$$
同理,$a^{1}
A^{[1]} =
\left[
\begin{array}{c}
\vdots & \vdots & \vdots & \vdots\
\alpha^{1} & \alpha^{1} & \cdots & \alpha^{1}\
\vdots & \vdots & \vdots & \vdots\
\end{array}
\right]
\left.
\begin{array}{r}
\text{$z^{1} = W^{1}x^{(i)} + b^{[1]}$}\
\text{$\alpha^{1} = \sigma(z^{1})$}\
\text{$z^{2} = W^{2}\alpha^{1} + b^{[2]}$}\
\text{$\alpha^{2} = \sigma(z^{2})
这种符号其中一个作用就是,可以通过训练样本来进行索引。这就是水平索引对应于不同的训练样本的原因,这些训练样本是从左到右扫描训练集而得到的。
在垂直方向,这个垂直索引对应于神经网络中的不同节点。例如,这个节点,该值位于矩阵的最左上角对应于激活单元,它是位于第一个训练样本上的第一个隐藏单元。它的下一个值对应于第二个隐藏单元的激活值。它是位于第一个训练样本上的,以及第一个训练示例中第三个隐藏单元,等等。
当垂直扫描,是索引到隐藏单位的数字。当水平扫描,将从第一个训练示例中从第一个隐藏的单元到第二个训练样本,第三个训练样本……直到节点对应于第一个隐藏单元的激活值,且这个隐藏单元是位于这
从水平上看,矩阵
对于矩阵
神经网络上通过在多样本情况下的向量化来使用这些等式。
3.5 向量化实现的解释(Justification for vectorized implementation)
3.5.1 向量化实现的解释
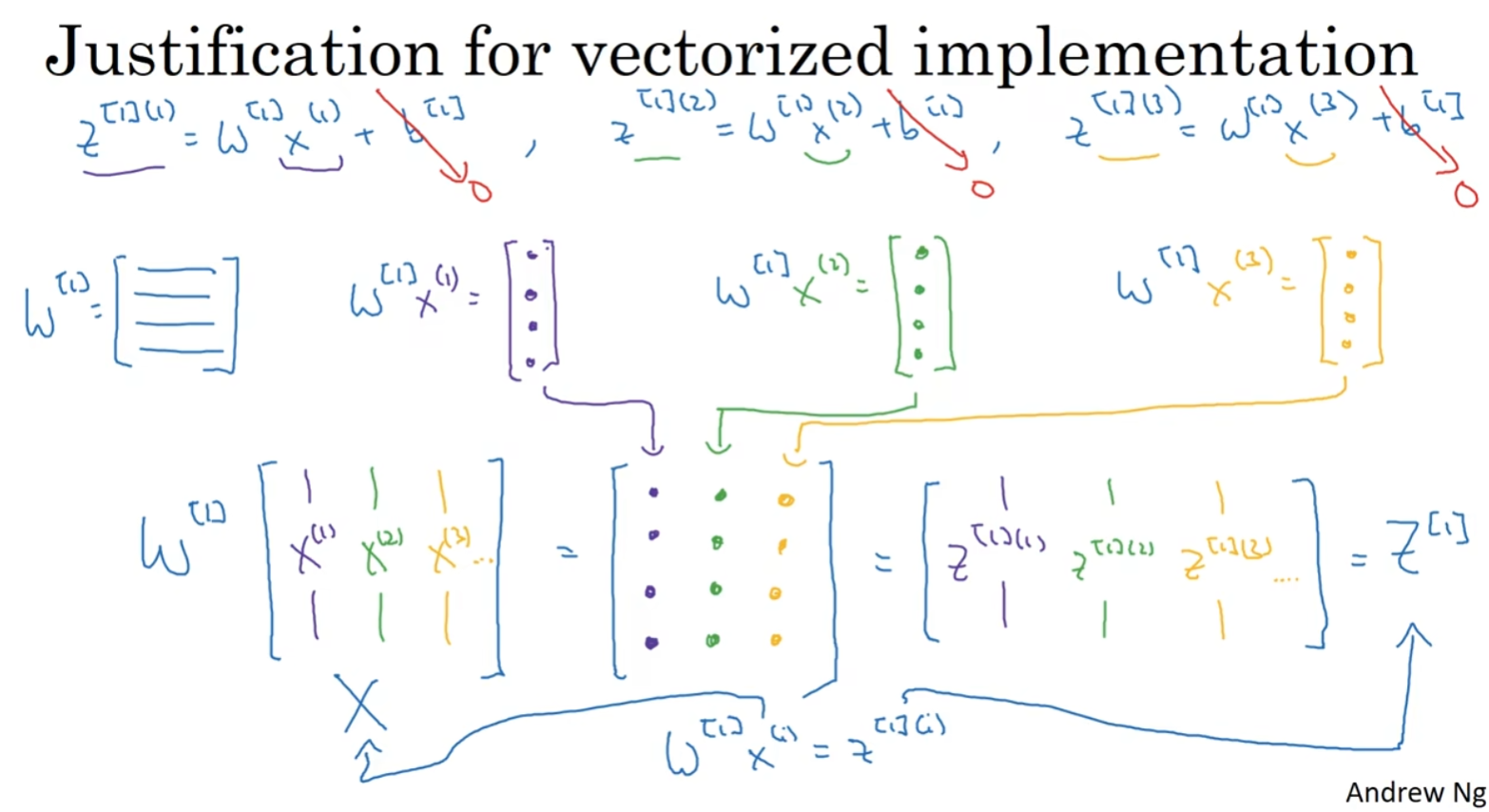
现在
$$
W^{[1]} x =
\left[
\right]
\left[
\begin{array}{c}
\vdots &\vdots & \vdots & \vdots \\
x^{(1)} & x^{(2)} & x^{(3)} & \vdots\\
\vdots &\vdots & \vdots & \vdots \\
\end{array}
\right]
=
\left[
\begin{array}{c}
\vdots &\vdots & \vdots & \vdots \\
w^{(1)}x^{(1)} & w^{(1)}x^{(2)} & w^{(1)}x^{(3)} & \vdots\\
\vdots &\vdots & \vdots & \vdots \\
\end{array}
\right]
=\\
\left[
\begin{array}{c}
\vdots &\vdots & \vdots & \vdots \\
z^{[1](1)} & z^{[1](2)} & z^{[1](3)} & \vdots\\
\vdots &\vdots & \vdots & \vdots \\
\end{array}
\right]
=
Z^{[1]}
$$
从图中可以看出,当加入更多样本时,只需向矩阵
所以从这里我们也可以了解到,为什么之前我们对单个样本的计算要写成
$z^{1} = W^{[1]}x^{(i)} + b^{[1]}

实际上
3.5.2 向量化总结
其实从第二章和第三章中讲向量化的过程就可以发现了,向量化最重要的事情就在于将for循环中的每个向量直接堆叠成矩阵,并通过矩阵计算的方式消除掉for循环但是得到一样的输出结果。
3.6 激活函数(Activation functions)
3.6.1 常见的激活函数
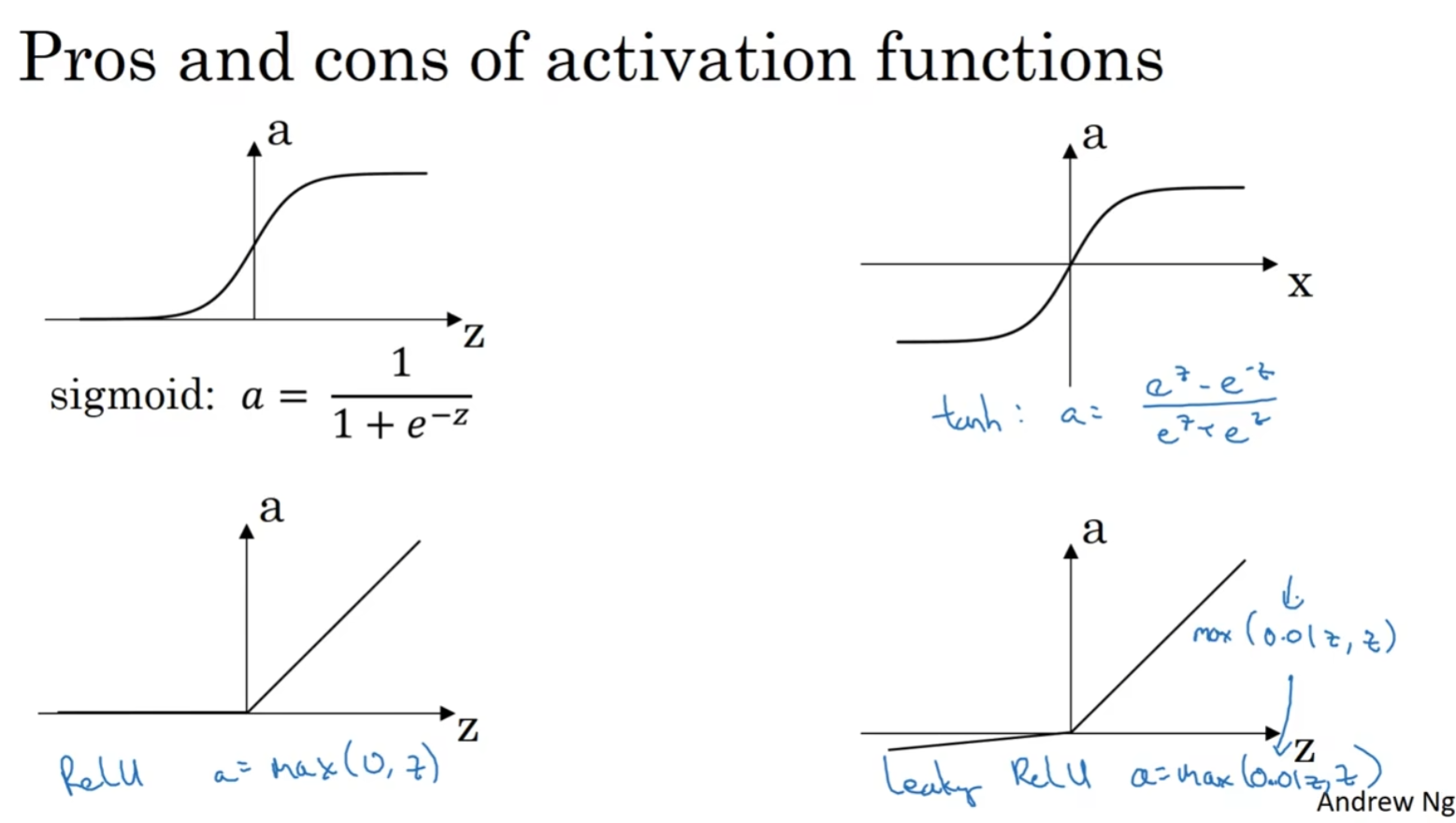
sigmoid函数:
tanh函数:
tanh函数是sigmoid的向下平移和伸缩后的结果。对它进行了变形后,穿过了
事实证明,如果在隐藏层上使用函数
修正线性单元函数(ReLU):
只要
Leaky ReLU:
当
ReLU和Leacky ReLU的优点:
第一,在
第二,sigmoid和tanh函数的导数在正负饱和区的梯度都会接近于0,这会造成梯度弥散,而ReLU和Leaky ReLU函数大于0部分都为常数,不会产生梯度弥散现象。(同时应该注意到的是,ReLU进入负半区的时候,梯度为0,神经元此时不会训练,产生所谓的稀疏性,而Leaky ReLU不会有这问题)
3.6.2 激活函数的选择
sigmoid激活函数:除了输出层是一个二分类问题基本不会用它。
tanh激活函数:tanh是非常优秀的,几乎适合所有场合。
ReLU激活函数:最常用的默认函数,如果不确定用哪个激活函数,就使用ReLU或者Leaky ReLU。
3.7 为什么需要非线性激活函数?(why need a nonlinear activation function?)
如果你是用线性激活函数或者叫恒等激励函数,那么神经网络只是把输入线性组合再输出(线性函数无论如何组合最终都是一个线性函数)。
不能在隐藏层用线性激活函数,可以用ReLU或者tanh或者leaky ReLU或者其他的非线性激活函数,唯一可以用线性激活函数的通常就是输出层;除了这种情况,会在隐层用线性函数的,除了一些特殊情况,比如与压缩有关的,否则几乎不可能。
3.8 激活函数的导数(Derivatives of activation functions)
1)sigmoid activation function
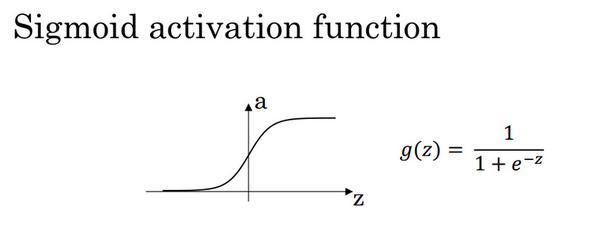
其具体的求导如下:
当
当
在神经网络中
- Tanh activation function
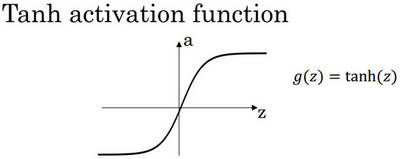
其具体的求导如下:
当
当
在神经网络中
3)Rectified Linear Unit (ReLU)
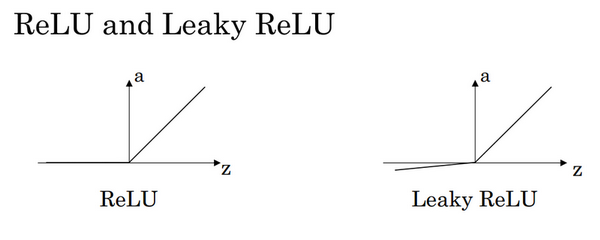
注:通常在
4)Leaky linear unit (Leaky ReLU)
与ReLU类似
注:通常在
3.9 神经网络的梯度下降(Gradient descent for neural networks)
正向传播方程如下:
forward propagation:
反向传播方程如下:
back propagation:
$ dz^{[1]} = \underbrace{W^{[2]T}{\rm d}z^{[2]}}{(n^{[1]},m)}\quad*\underbrace{g’^{[1]}}{activation ; function ; of ; hidden ; layer}*\quad\underbrace{(z^{[1]})}{(n^{[1]},m)}
这些都是针对所有样本进行过向量化,np.sum是python的numpy命令,axis=1表示水平相加求和,keepdims是防止python输出那些古怪的秩数
还有一种防止python输出奇怪的秩数,需要显式地调用reshape把np.sum输出结果写成矩阵形式。
3.10(Math)直观理解反向传播(Backpropagation intuition)
3.10.1 Logistic Regression
回想一下逻辑回归的公式
所以回想当时我们讨论逻辑回归的时候,我们有这个正向传播步骤,其中我们计算
$$
\underbrace{
\left.
\right}
}{dw={dz}\cdot x, db =dz}
\impliedby\underbrace{z={w}^Tx+b}{dz=da\cdot g^{‘}(z),
g(z)=\sigma(z),
{\frac{dL}{dz}}={\frac{dL}{da}}\cdot{\frac{da}{dz}},
{\frac{d}{ dz}}g(z)=g^{‘}(z)}
\impliedby\underbrace{ {a = \sigma(z)}
\impliedby{L(a,y)}}_{da={\frac{d}{da}}{L}\left(a,y \right)=(-y\log{\alpha} - (1 - y)\log(1 - a))^{‘}={-\frac{y}{a}} + {\frac{1 - y}{1 - a}{}} }
$$

3.10.2 Neural Network
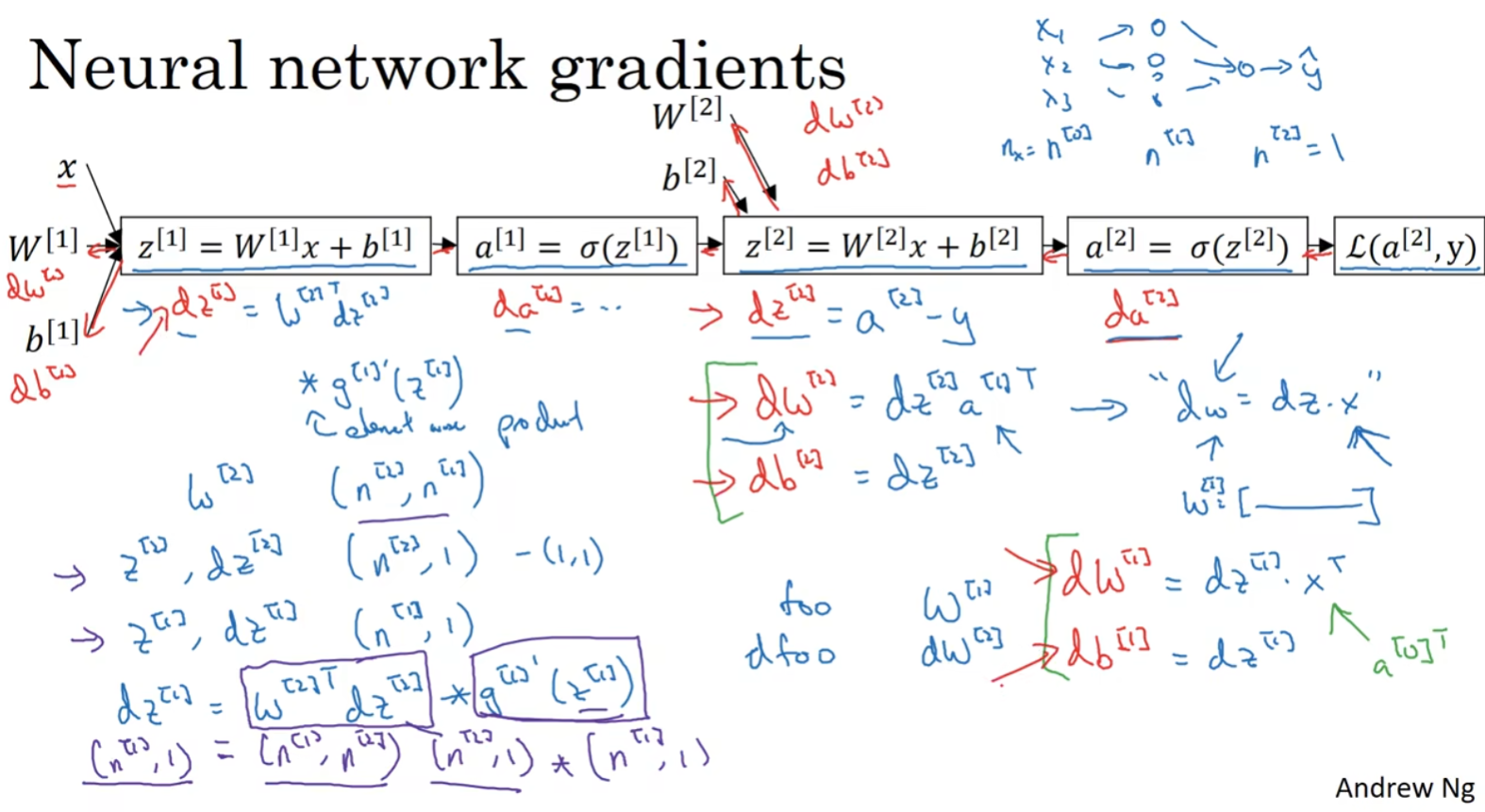
神经网络的计算中,与逻辑回归十分类似,但中间会有多层的计算。下图是一个双层神经网络,有一个输入层,一个隐藏层和一个输出层。
前向传播:
计算
反向传播:
向后推算出
(注意:逻辑回归中;为什么
公式3.41:
公式3.42:
注意:这里的矩阵:
证明过程:
见公式3.42,其中
实现后向传播有个技巧,就是要保证矩阵的维度相互匹配。最后得到
可以看出
由:
得到:
$$
Z^{[1]} =
\left[
\begin{array}{c}
\vdots &\vdots & \vdots & \vdots \
z^{1} & z^{1} & \vdots & z^{1} \
\vdots &\vdots & \vdots & \vdots \
\end{array}
\right]
$$
注意:大写的
下图写了主要的推导过程:
 公式3.44:
公式3.44:
公式3.45:
公式3.46:
公式3.47:
$\underbrace{dZ^{[1]}}{(n^{[1]}, m)} = \underbrace{W^{[2]T}dZ^{[2]}}{(n^{[1]}, m)}*\underbrace{g[1]^{‘}(Z^{[1]})}_{(n^{[1]}, m)}
3.11 随机初始化(Random Initialization)
对于一个神经网络,如果你把权重或者参数都初始化为0,那么梯度下降将不会起作用。
3.11.1 举个栗子
有两个输入特征,
因此与一个隐藏层相关的矩阵,或者说
那这个问题如果按照这样初始化的话,你总是会发现
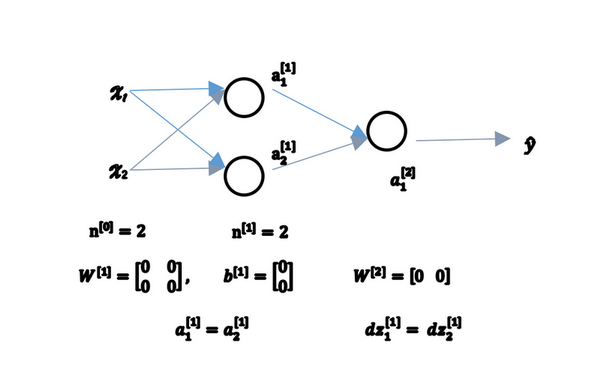
图3.11.1
但是如果你这样初始化这个神经网络,那么这两个隐含单元就会完全一样,因此他们完全对称,也就意味着计算同样的函数,并且肯定的是最终经过每次训练的迭代,这两个隐含单元仍然是同一个函数,令人困惑。
由此可以推导,如果你把权重都初始化为0,那么由于隐含单元开始计算同一个函数,所有的隐含单元就会对输出单元有同样的影响。一次迭代后同样的表达式结果仍然是相同的,即隐含单元仍是对称的。通过推导,两次、三次、无论多少次迭代,不管你训练网络多长时间,隐含单元仍然计算的是同样的函数。因此这种情况下超过1个隐含单元也没什么意义,因为他们计算同样的东西。当然更大的网络,比如你有3个特征,还有相当多的隐含单元。
3.11.2 随机初始化参数
把np.random.randn(2,2)(生成高斯分布),通常再乘上一个小的数,比如0.01,这样把它初始化为很小的随机数。然后
$W^{[1]} = np.random.randn(2,2);;0.01;,;b^{[1]} = np.zeros((2,1))
PS:为什么是0.01嘞?
我们通常倾向于初始化为很小的随机数。因为如果你用tanh或者sigmoid激活函数,或者说只在输出层有一个Sigmoid,如果(数值)波动太大,当你计算激活值时
如果np.random.randn((1,2)),我猜会是乘以0.01。
